그룹화 기준
– 테이블의 모든 행을 특정 열이 동일한 행으로 그룹화
– group by 절이 없으면 테이블의 모든 행을 하나의 그룹으로 취급
– 그룹화 기준 select 절에는 특정 열만 사용할 수 있습니다.. 비열을 사용하면 오류가 발생합니다.
– 그룹화 또한 0을 그룹으로 취급합니다.하다.
– 가상컬럼으로 그룹화도 가능합니다.
– 그룹화할 때 열 순서는 중요하지 않습니다.
– Group By에서 여러 열을 그룹화할 때 고유 처리와 마찬가지로 값이 같은 행을 두 개의 열로 그룹화합니다.
ex) 부서별 급여 합계
select
dept_code,
sum(salary) sum_sal,
trunc(avg(salary)) avg_sal
from
employee
group by
dept_code --group_by에서는 null도 그룹으로 처리함
order by
sum(salary) desc;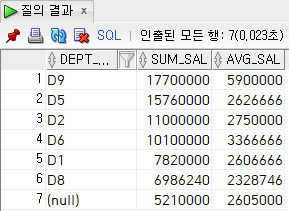
ex) 근무 연도별 직원 수 쿼리(테이블 별칭이 아님)
select
extract(year from hire_date) hire_year,
count(*) cnt
from
employee e
group by
extract(year from hire_date)
order by
hire_year; 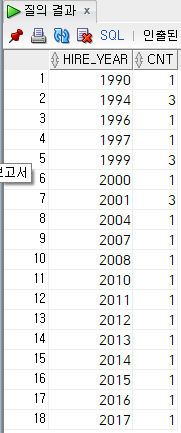
Extract(~)와 같은 가상 컬럼도 조회가 가능한 것을 확인할 수 있습니다.
ex) 부서별, 직위별 직원 수 조회
-> 두 열 사이에 동일한 값을 가진 행을 그룹화합니다. B. 뚜렷한
select
dept_code,
job_code,
count(*) cnt
from
employee
group by
dept_code,job_code;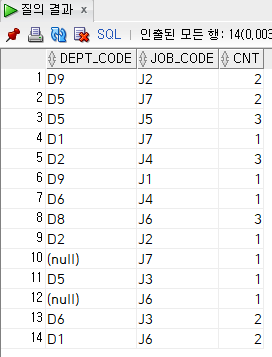
가지다
-조건문, 그룹화 결과 행에 대한 결과 집합을 포함할지 여부처리할 구문
ex) 인턴 제외, 부서별 평균 급여가 300만원 이상인 부서만 검색(부서코드, 평균 급여)
select
dept_code,
trunc(avg(salary)) avg_sal
from
employee
where
dept_code is not null
group by
dept_code
having
avg(salary)>=3000000;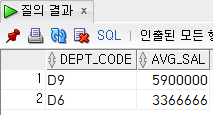
예) 두 명 이상의 직원을 관리하는 관리자의 관리자 수 및 직원 수를 쿼리합니다.
방법 1
select
manager_id,
count(*) cnt
from
employee
where
manager_id is not null
group by
manager_id
having
count(*) >=2 ;방법 2
select
manager_id,
count(*) cnt
from
employee
group by
manager_id
having
count(*) >=2 and manager_id is not null;방법 3
select
manager_id,
count(*) cnt
from
employee
group by
manager_id
having
count(manager_id)>=2; --count자체가 null을 세지 않음답은 전부다
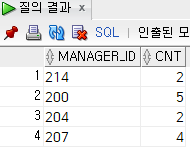
로 나온다
where 대신 have에 조건을 작성할 수 있습니다.
롤업 | 주사위
– 그룹별로 계산된 결과의 소계를 반환하는 함수
– group by 절에서만 사용
– 롤업 : 지정된 열에 대한 단방향 소계
– 주사위 : 지정된 열에 대한 양방향 소계
select
dept_code,
count(*)
from
employee
group by
rollup(dept_code)
order by
dept_code;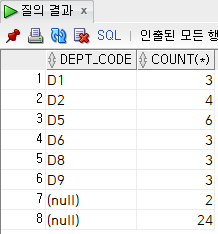
7행의 0은 dept_code가 없는 두 명의 인턴입니다.
8행의 0은 롤업으로 계산한 24명의 합입니다.
구분하는 한 가지 방법은 그룹화를 사용하는 것입니다.
그룹화(값)
실제 데이터 (0) , 집계 프로세스 중에 생성된 데이터 (하나) 분리
select
decode(grouping(dept_code),0,nvl(dept_code,'인턴'),1,'전체') dept_code,
count(*)
from
employee
group by
rollup(dept_code)
order by
dept_code;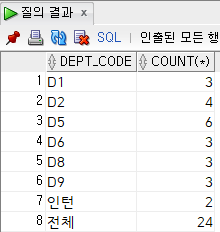
연결하다
– 둘 이상 테이블 레코드를 조인하여 가상 테이블 관계 생성문법을 하기 위해
– 참조 열이 있는 두 테이블의 레코드 조인
관계를 맺다
1. 결합하다 2. 결합하다 두 가지 가능성이 있습니다.
왜 가입)
직원 “송종기”의 부서명을 조회하는 방법입니다.
select dept_code from employee where emp_name="송종기";--D9
select dept_title from department where dept_id ='D9'; --총무부다음을 두 번 거쳐야 하기 때문에 번거롭고 코드가 길다.
조인은 그것을 한 번에 해결합니다.
select d.dept_title
from
(employee e join department d
on e.dept_code = d.dept_id)
-- dept_code와 dept_id가 같은 행끼리 연결해서 붙인 것임.
where
e.emp_name="송종기";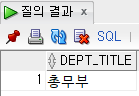
JOIN 분류
1. 동등한 조인 : 조인 참조절(on) = 동치 비교로 조인(이용률 95%)
2. 비동등 조인 : 조인 표준절에서(on) = 동등 비교를 사용하지 않는 조인(이용률 5%)
예) !=, between and , in, 같은 연산자는 null
JOIN 방식의 분류
1. ANSI 표준 문법 : 합류하다, 큐
2. Oracle 관련 문법 : ,(쉼표), where 절 사용
EQUI-JOIN 분류
1. 내부 연결: 교차
2. 외부 조인: 유니온
왼쪽 외부 연결
오른쪽 외부 조인
전체 외부 조인
3. 교차 연결
4. 참여하기
5. 복수가입 복수가입
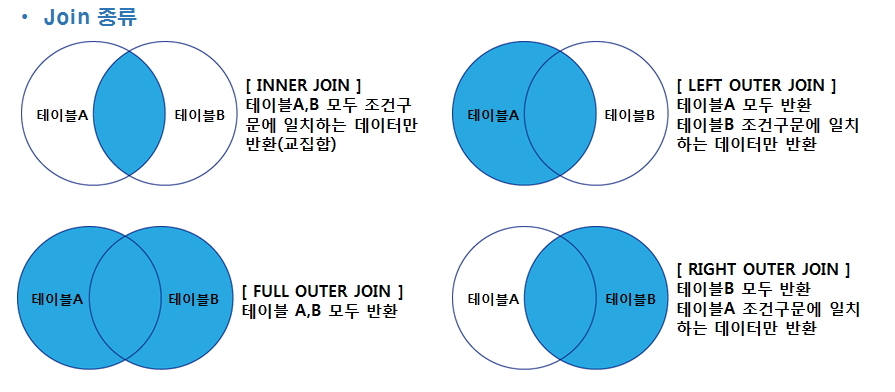
내부 연결
– 내부 가입. 두 테이블의 교차점을 지정합니다.
– 각 테이블에서 참조 열이 null이고 상대 테이블에 일치하는 행이 없는 행 제외.
– inner 키워드는 생략 가능합니다. (내부) 조인으로 생성
예
직원 | 부서 테이블의 내부 조인.
직원.dept_code = 부서.dept_id
내부 조인
직원 테이블에서 dept_code가 null인 경우 2번 라인 제외BE.
부서 테이블의 employee.dept_code에서 사용되지 않음 라인 D3, D4, D7 제외
* 직원 중에서 선택;
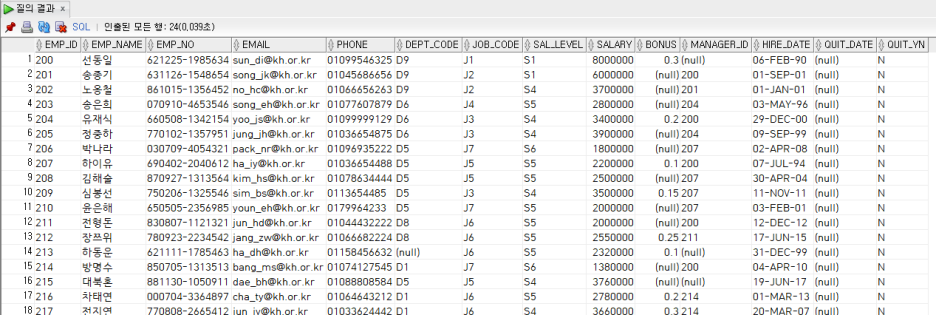
부서에서 *로 전화하십시오.
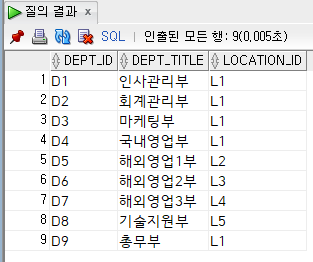
select
e.emp_name,
d.dept_title
from
employee e inner join department d
on e.dept_code = d.dept_id;내부 조인 결과(22행 출력)

외부 조인
외부 연결
왼쪽/오른쪽 테이블을 기준으로 조인합니다. 기본 테이블에 누락된 행이 없습니다.
outer 키워드는 생략할 수 있습니다. 왼쪽(외부) 조인 | 오른쪽(외부) 조인
예) 왼쪽 외부 조인
직원 테이블을 기반으로 하는 모든 행을 포함합니다.
24행 = 22행(내부 조인) + 2행(내부 null 값)
select
emp_name,
dept_title
from
employee e left outer join department d
on e.dept_code = d.dept_id;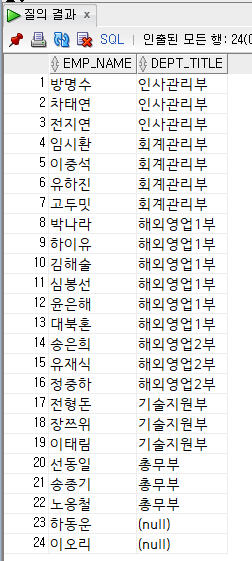
내적 연결 결과를 비교해 보면 하동운과 이오리가 추가된 것을 알 수 있다.
ex) 오른쪽 외부 조인
부서 테이블을 기반으로 하는 모든 행을 포함합니다.
행 25 = 행 22( 내부 조인 ) + 행 3(직원이 없는 D3, D4, D7 부서)
select
d.dept_title,
e.emp_name
from
employee e right outer join department d
on e.dept_code = d.dept_id;
마케팅 섹션, 국내 판매 섹션, 해외 판매 섹션이 null 값인데도 출력되는지 확인할 수 있습니다.
예) 완전 외부 조인
왼쪽과 오른쪽이 모두 표준이므로 왼쪽과 오른쪽 테이블에서 제외되는 행은 없습니다.
27행 = 22행(내부 조인) + 2행(인턴) + 3행(직원이 없는 부서 D3,D4,D7)
select
e.emp_name,
d.dept_title
from
employee e full outer join department d
on e.dept_code = d.dept_id;
27행이 인쇄되는 것을 볼 수 있습니다.
이렇게 내부 조인과 외부 조인에 대해 알아보았습니다.
당신은 PK와 FK를 언급했지만 나는 그것을 짧게 유지하고 아래에 요약합니다..!