
드림부스는 구글 연구팀과 보스턴대학교 연구진이 2022년 개발한 생성적 딥러닝 모델이다. Dreambooth는 기존 텍스트 대 이미지 목업을 최적화하거나 새 이미지를 생성할 수 있습니다. Dreambooth는 다른 확산 모델(예: DALL.E 2, Midjourney, Stable Diffusion)이 할 수 없거나 할 수 없는 작업을 수행할 수 있습니다.
Dreambooth는 사진 부스와 비슷하지만 피사체를 캡처한 후에는 꿈에서 보는 모든 곳에서 함께 조각을 맞출 수 있습니다. 예를 들어, 자신의 사진을 업로드하고 “수트를 입은 전신 사진”을 입력하면 Dreambooth는 귀하의 사진을 기반으로 정장을 입은 귀하의 사진을 생성합니다. 특정 그림이나 물체를 그리는 법을 배울 수도 있습니다.
Dreambooth 비헤이비어 트리
텍스트 반전과 마찬가지로 DreamBooth도 일부 이미지(보통 3-5개)를 입력하고 DreamBooth는 조정된 이미지와 몇 가지 다른 확산 모델을 사용하여 다양한 맥락에서 테마가 있는 개인화된 이미지를 생성합니다.
입력으로 이미지가 주어지면 피팅된 이미지 및 기타 확산 모델이 고유한 식별자를 찾아 주제와 연결합니다. 파생은 고유 식별자를 사용하여 다양한 컨텍스트에서 주제를 합성합니다.
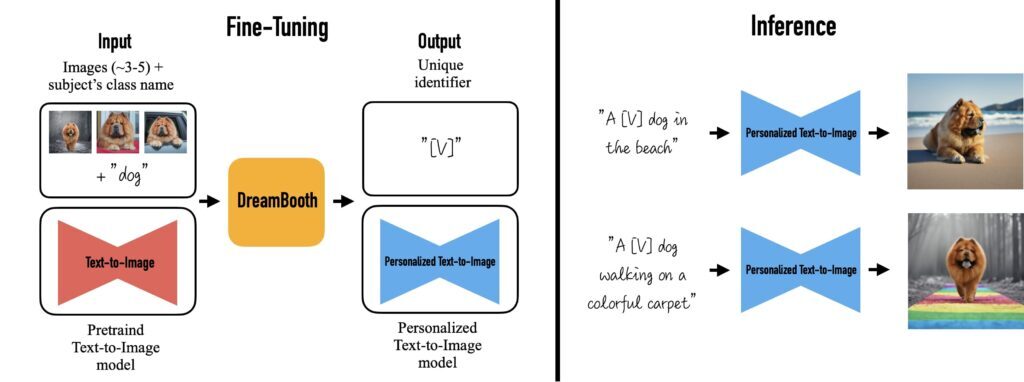
Dreambooth와 텍스트 반전의 차이점은 무엇입니까?
차이점은 Dreambooth는 전체 모델을 다듬는 반면 Textual Inversion은 희귀 단어를 재사용하는 대신 새 단어를 삽입하고 모델의 일부에 포함된 텍스트만 다듬는 것입니다.
드림부스 사용해보기
먼저 공부할 사진 3~5장을 준비합니다.
화면이 좋을수록 좋습니다.
1. 이미지 크기 조정
학습에 이미지를 사용하려면 먼저 v1 모델로 학습할 수 있도록 이미지를 512×512 픽셀로 조정해야 합니다.
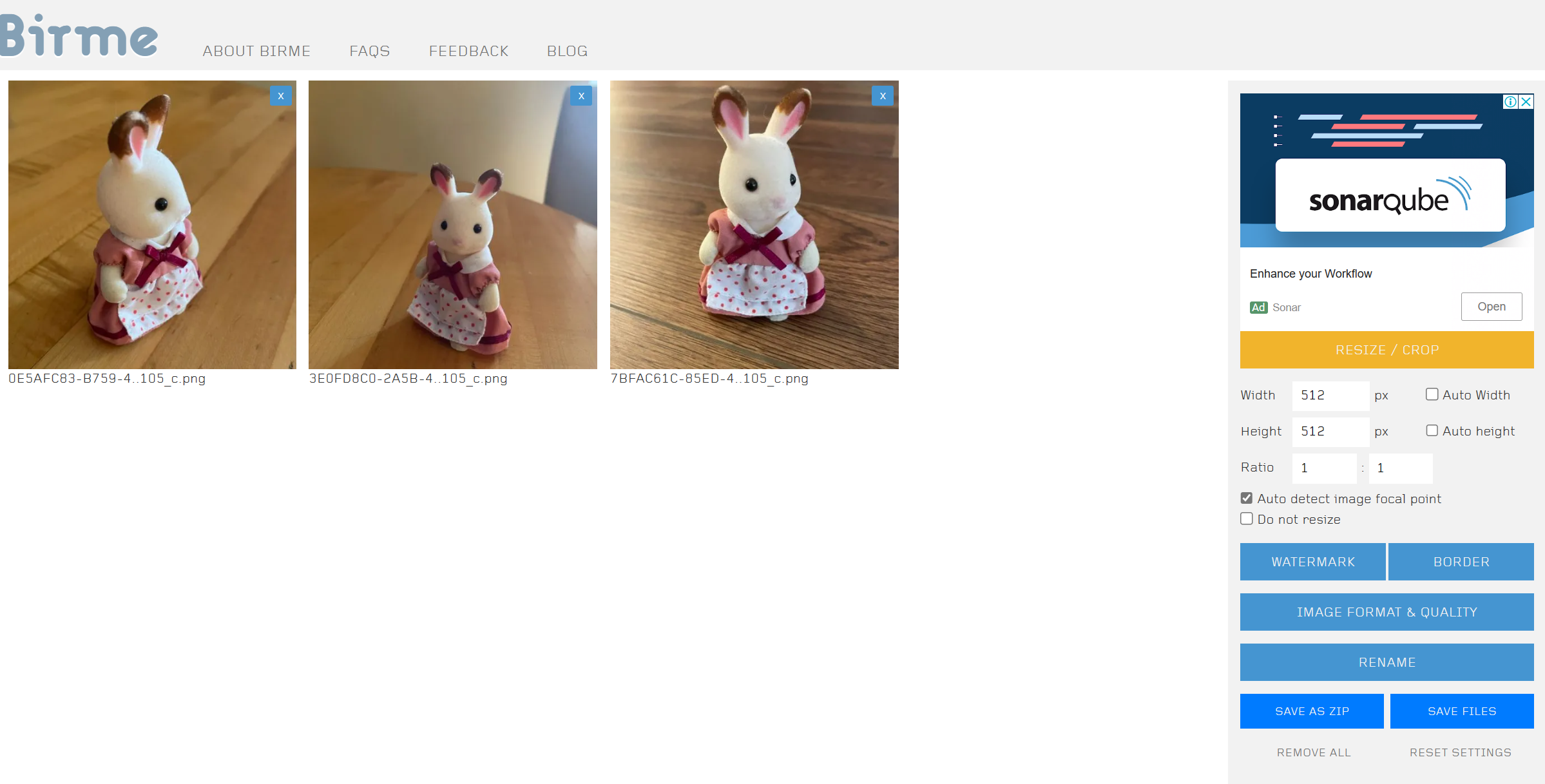
BIRME는 편리한 이미지 크기 조정 페이지입니다.
BIRME – 간편한 대량 이미지 크기 조정 2.0(온라인 및 무료)
BIRME – 간편한 대량 이미지 크기 조정 2.0(온라인 및 무료)
Birme 정보 버전 2의 새로운 기능 NEW* WebP 형식 지원 추가 이제 각 사진의 초점을 개별적으로 조정할 수 있습니다. 이전에 사용한 설정을 자동으로 로드합니다. 자동 초점 감지. 대량으로 파일 이름 바꾸기
www.birme.net
1) 이미지를 BIRME 페이지로 끌어다 놓습니다.
2) 피사체가 적절하게 보이도록 각 이미지의 캔버스를 조정합니다.
3) 너비와 높이가 모두 512픽셀인지 확인합니다.
4) 파일 저장을 클릭하여 크기가 조정된 이미지를 컴퓨터에 저장합니다.
– 오른쪽 하단의 파일 저장을 클릭하여 컴퓨터에 저장합니다.
이미지 출처:https://stable-diffusion-art.com/wp-content/uploads/2022/12/dreambooth_training_images.zip
2. 드림부스 학습
오늘은 구글 코랩으로 배워보겠습니다.
Colab 코드는 다음과 같습니다.
Colab 사용법을 알고 있다고 가정하고 오늘 계속 진행해 보겠습니다.
DreamBooth_Stable_Diffusion_SDA.ipynb – 협업(google.com)
DreamBooth_Stable_Diffusion_SDA.ipynb
Python 노트북 실행, 공유 및 편집
colab.research.google.com
계속하려면 위의 Colab을 열고 사본을 저장하세요.
Colab 노트북을 열면 아래와 같이 DreamBooth에 대한 코드가 표시됩니다.
그리고 왼쪽에 있는 플레이 버튼을 누르면 원이 돌면서 실행됩니다.
Google 드라이브 로그인 및 권한 요청이 표시되면
로그인하고 허용 버튼을 클릭합니다.
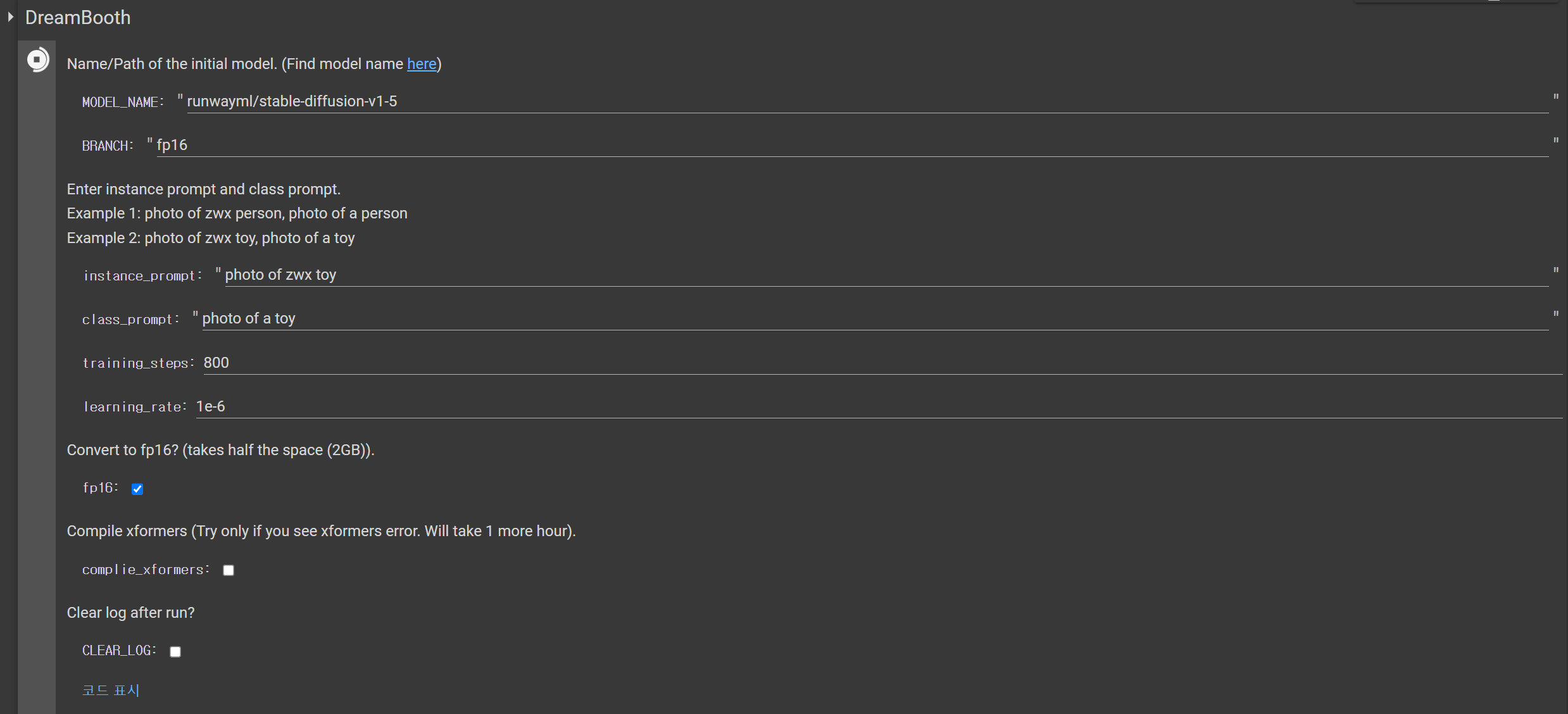
인스턴스 프롬프트를 zwx 장난감 사진으로 설정했습니다.
그리고 수업 프롬프트를 장난감 사진으로 설정합니다.
나는 결정했다.
이렇게 하면 아래와 같이 이미지를 업로드하라는 메시지가 표시됩니다.

파일 선택을 클릭하고 이전에 준비한 모든 이미지를 삽입하고 선택합니다.
그러면 다음과 같이 설치가 진행됩니다.
설치 시간이 꽤 오래 걸립니다.
자유 시간을 계속하십시오.
20~30분 정도 소요되는 것 같습니다.
그런 다음 이미지를 만들 차례입니다.
미리 결정된 객체인 zwx를 반 고흐 이미지 스타일로 만들어 봅시다.
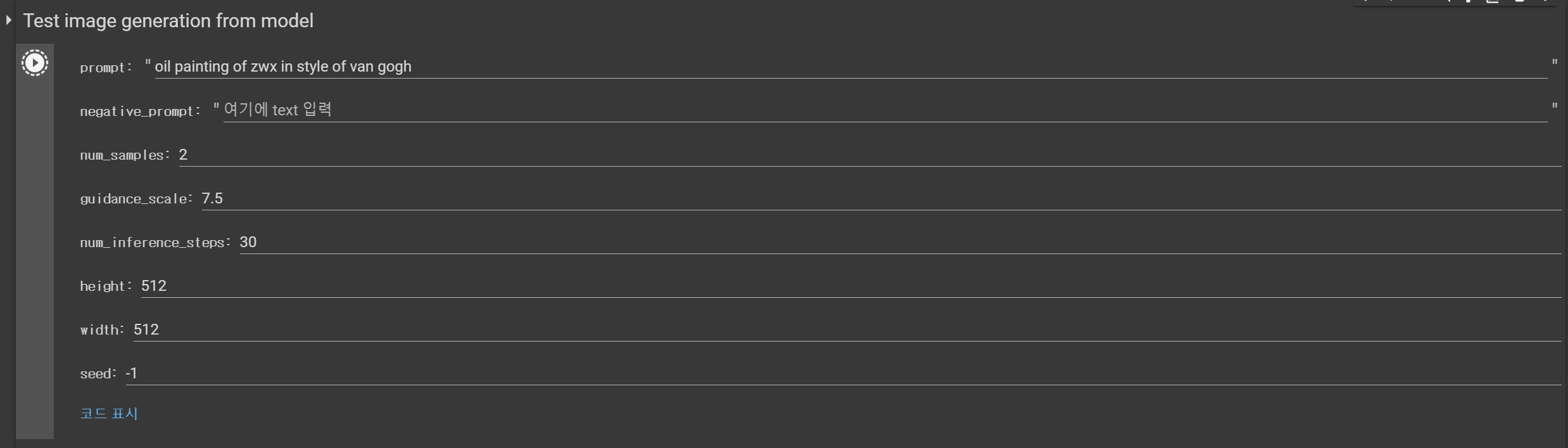
그리고 내가 실행하면


결과는 위와 같은 반 고흐 스타일의 토끼 그림입니다.
오늘 수고하셨습니다.
2023/03/12 – (AI 설명) – 확산 모델 중 LoRA 모델에 대해 알아보고 이미지 생성
2023-03-11 – (AI 설명) – Diffusion Technologies에서 Text Inversion을 속성으로 알아봅니다.
확산 기술에서는 속성으로서 텍스트 반전에 대해 알아봅니다.
안정적인 확산은 생성 커뮤니티에서 매우 뜨겁고 생성 AI의 발전이 빠르게 진행되고 있습니다. 그 중 하나는 텍스트 반전입니다. 아래는 논문에 게재될 공식 명칭입니다. 사진
nomadlabs.co.kr
2023.03.02 – (No-coding AI) – Windows PC에 Stable Diffusion WebUI를 설치하여 실사 사진을 만드는 방법
Windows PC에서 사실적인 사진 생성을 위한 Stable Diffusion WebUI를 설치하는 방법
WebUI를 통해 PC에 Stable Diffusion을 설치하는 방법을 살펴보겠습니다. 설치가 완료되면 아래와 같은 이미지를 생성할 수 있습니다. AI 모델 변경시 애니메이션 풍의 사진 실사 사진 하프 스페이스
nomadlabs.co.kr
2023년 3월 3일 – (노코딩 AI) – 반사실적인 사진 생성. Stable Diffusion 웹 UI를 사용하여 모델을 병합하는 방법